Une nouvelle version lancée ce jeudi
La Base biographique de la BIU Santé a été restructurée, et sa nouvelle version vient d’être publiée.

La Base biographique, c’est aujourd’hui un ensemble de 46231 fiches nominatives, et de 83761 sources distinctes. On peut espérer y trouver des informations et des références bibliographiques sur toute personne ayant contribué à l’histoire de la santé, de tous les lieux, de toutes les époques.
Réorganisation des données
Sans doute l’usager occasionnel de la Base biographique ne sera-t-il pas bouleversé lors de son prochain passage par le changement qui s’est opéré.
C’est même notre souhait que ses habitudes de recherche ne soient pas trop perturbées. Un outil de recherche doit être aussi simple que possible, et il n’est pas nécessaire qu’il paraisse perfectionné ou innovant, mais seulement qu’il rende le service qu’il doit rendre, et mieux qu’hier si possible.
Donc, notre chercheur percevra peut-être, cela nous l’espérons, une meilleure organisation des données. Il trouvera peut-être que les informations qui sont données sont plus claires et mieux expliquées.
Enrichissements
Un fait essentiel est toujours difficilement perceptible lorsqu’on consulte une base de données : c’est la dimension de ce réservoir d’informations. Sur ce point, nous avons la satisfaction d’annoncer que la nouvelle version contient nettement plus de données que la précédente.
Notamment, le dépouillement systématique de quelques grosses sources biographiques systématiques (par exemple le Dictionnaire historique de la médecine ancienne et moderne d’Eloy (1778), le Dictionnaire encyclopédique des sciences médicales de Dechambre (1864- 1889), ou le Dictionary of medical biography de W. et H. Bynum (2007) comblent des lacunes qui résultaient du mode de constitution de la version précédente de la base biographique. Le développement de celle-ci était en effet, légitimement d’ailleurs et très utilement, fondé surtout sur le dépouillement au fil de l’eau des entrées de documents dans les fonds de la bibliothèque. On y trouvait ainsi et on y trouve toujours des sources rarement citées ailleurs, mais on pouvait regretter que certains noms importants ne soient pas du tout présents, parce que le hasard des publications et des entrées ne les avaient pas fait rencontrer. Ces lacunes devraient être plus rares.
Prise en charge de données hétérogènes
D’autre part, la nouvelle base biographique est structurée pour pouvoir prendre en charge des données de nature très hétérogène. Essayons de nous expliquer.
Et ceci se passait dans des temps très anciens…
À l’origine, la Base biographique de la BIU Santé était un fichier bio-bibliographique. Les fiches, de très petit format, comportaient un nom, quelques informations de base (dates et lieux, profession, parfois quelques indications sur la carrière), et surtout les références bibliographiques de documents imprimés et d’articles présents dans la collection de la bibliothèque.
Ce fichier a été transformé au début de notre siècle en une base de données informatique, sur le même modèle.
Complexification
Puis, peu à peu, grâce aux possibilités offertes par l’informatique, des données assez diverses se sont agglomérées autour de ce noyau principal de références bibliographiques (qui continuait à se développer).
Aux noms des personnes présentes ont été liés les portraits numérisés dans la Banque d’images et de portraits.
On a signalé également des portraits qui n’ont pas fait l’objet d’une numérisation (souvent pour des raisons de droit de propriété intellectuelle), mais qui existent dans la collection.
On y a adjoint, grâce à la coopération de la bibliothèque de l’Académie de médecine, les appartenances à cette compagnie (“Membre de l’Académie de médecine”), ou la présence d’un “Dossier à l’Académie de médecine”. On a versé l’intégralité du contenu du Fichier Laborde, un important dépouillement d’archives effectué sous la direction de Léon de Laborde, garde général des Archives de l’Empire à partir de 1857, qui permet notamment de repérer tout un monde de médecins et de chirurgiens du XVIe et du XVIIe siècles.
Des chercheurs, Pierre Moulinier et Jean-Marie Mouthon, nous ont permis de charger des dépouillements d’archives et des notices biographiques rédigés par eux.
À mesure que les années passaient, la base de données devenait ainsi plus riche, mais aussi plus compliquée, et plus difficile à gérer et à documenter.
Une hétérogénéité inévitable
Pourtant, il était évident que cette complexité allait encore croître : en effet, le développement de la numérisation, à la BIU Santé et dans le monde, rendait indispensable de pouvoir ajouter à la base biographique une très grande diversité de données directement accessibles en ligne et de partout, et non seulement les nécessaires références aux collections imprimées consultables sur place à la bibliothèque.
C’est cette diversité de données que nous essayons de mieux gérer dans notre nouvelle base en ligne.
On trouvera déjà de très nombreux liens entre la base biographique et les ressources biographiques que fournit la bibliothèque numérique Medic@. Des milliers de liens ont été créés, principalement vers des dictionnaires pour l’instant, et vers les précieux “Titres et travaux scientifiques”, ces curriculum-vitae dont la bibliothèque conserve une riche collection largement numérisée.  Mais nous verserons prochainement d’autres ressources.
Mais nous verserons prochainement d’autres ressources.
Dans les prochains mois, la base biographique permettra ainsi d’exploiter le considérable fichier manuscrit que la famille de Jacques Léonard a donné à la BIUM lors du décès de ce chercheur en 1988, qui est constitué par le dépouillement de milliers de dossiers d’archives sur des médecins de l’ouest de la France au XIXe siècle.
Nous travaillons également à repérer dans les périodiques que nous avons numérisés les nécrologies innombrables qu’ils contiennent. Si nous en avions les moyens, nous pourrions également nous attaquer à des ressources qui se trouvent dans d’autres bibliothèques numériques ou bases de données en ligne.
Nous serions heureux de nouer de nouvelles collaborations avec des chercheurs ou des institutions, que ce soit pour signaler des ressources distantes ou pour inclure directement de nouvelles biographies rédigées. Le champ est immense, plus grand que nos forces. L’intérêt permanent du public pour la biographie nous semble justifier des efforts importants.
Les utilisateurs verront également que nous avons fait notre possible pour documenter les dépouillements que nous avons effectués. Il est indispensable d’accumuler des données : il est utile aussi de dire d’où elles viennent, et quelles sont les sources qui ont été exploitées (et donc quelles sont celles qui ne l’ont pas été). De plus, certaines de ces ressources – le fichier Laborde déjà nommé par exemple – ont absolument besoin d’être expliquées : la documentation des sources est une nécessité qui est liée à l’hétérogénéité du contenu. Cet effort de documentation nous est d’ailleurs indispensable à nous aussi, pour savoir où nous en sommes et mieux organiser nos dépouillements.
Une base techniquement plus ouverte
Enfin, la base nouvelle manière est plus ouverte, et nous nous efforcerons de l’ouvrir encore davantage dans la prochaine étape technique de son développement.
Ouverture aux moteurs de recherche
Jusque là, la base biographique appartenait au «web caché», comme on dit : on n’en trouvait pas tout le contenu par l’intermédiaire des moteur de recherche du web comme Google. La nouvelle architecture devrait permettre que les moteurs de recherche viennent lire le contenu de la base, et le proposent donc à leurs utilisateurs, c’est-à-dire à nous tous.

Les identifiants d’autorité à l’horizon
Notre prochaine étape technique, dans la mesure de nos forces, sera de lier nos données avec d’autres jeux de données disponibles, plus précisément d’abord avec ce que les professionnels de la documentation appellent les «données d’autorité».
Les données d’autorité répondent d’abord à un besoin pratique de gestion des collections, en différenciant les homonymes dans les catalogues, ou en liant entre eux les différents noms d’une même personne ; ainsi on peut indiquer quel est le Jean Durand qui a écrit un certain livre (qui n’est pas le Jean Durand qui a écrit tel autre livre) ; et on peut fournir, à celui qui cherche les ouvrages de Jacobus Sylvius, ceux qui sont notés sous le nom de Jacques Dubois.
Mais l’informatique a donné un rôle accru à ces données d’autorité et aux numéros d’identification qui les accompagnent : si vous savez quel est le numéro qui désigne une personne, vous avez en principe la possibilité de joindre ensemble toutes les informations qui contiennent ce numéro d’identification. Par exemple, si vous savez que Sigismond Jaccoud a un identifiant 64023688 dans la base de données internationale VIAF, vous pouvez récupérer les informations qui s’y trouvent liées parce qu’elles utilisent également cet identifiant, notamment les diverses pages Wikipedia (https://en.wikipedia.org/wiki/Sigismond_Jaccoud, https://fr.wikipedia.org/wiki/Sigismond_Jaccoud, etc.), les données de Worldcat Identities, mais aussi les données bibliographiques qui concernent Jaccoud dans les catalogues de bibliothèques, etc. Ce numéro pourrait permettre aussi, en principe, que d’autres outils informatiques viennent à leur tour puiser dans la Base biographique.
L’usage de ces identifiants devrait se développer dans les temps qui viennent : nous espérons que la base biographique est aujourd’hui mieux préparée à s’intégrer dans le paysage documentaire qui se met en place. Le chemin, il faut le dire, est encore un peu long pour nous, mais l’essentiel est de pouvoir le commencer.
Nous comptons sur les utilisateurs pour nous signaler les défauts qu’ils trouveront, et nous faisons appel à leur indulgence critique.
Jean-François Vincent
24 mai 2018
 La prochaine «
La prochaine « 
 Sans surprise PubMed est plébiscité pour la recherche de littérature : 126 personnes déclarent l’utiliser. Viennent ensuite Google Scholar (104), Web of Science (36), Scopus (17), Mendeley (9) et Paperity (8), entre autres. Le même classement se retrouve à peu près
Sans surprise PubMed est plébiscité pour la recherche de littérature : 126 personnes déclarent l’utiliser. Viennent ensuite Google Scholar (104), Web of Science (36), Scopus (17), Mendeley (9) et Paperity (8), entre autres. Le même classement se retrouve à peu près  Du côté des logiciels de bibliographie, Zotero est en tête (63 utilisateurs), talonné par EndNote (53), puis Mendeley (10), Papers (6), ReadCube (3), JabRef (3). La situation est bien différente
Du côté des logiciels de bibliographie, Zotero est en tête (63 utilisateurs), talonné par EndNote (53), puis Mendeley (10), Papers (6), ReadCube (3), JabRef (3). La situation est bien différente  La nouvelle est passée relativement inaperçue, notamment en France : pour la première fois, un pays entier, la Finlande, a rendu public le montant des abonnements payés aux éditeurs scientifiques.
La nouvelle est passée relativement inaperçue, notamment en France : pour la première fois, un pays entier, la Finlande, a rendu public le montant des abonnements payés aux éditeurs scientifiques.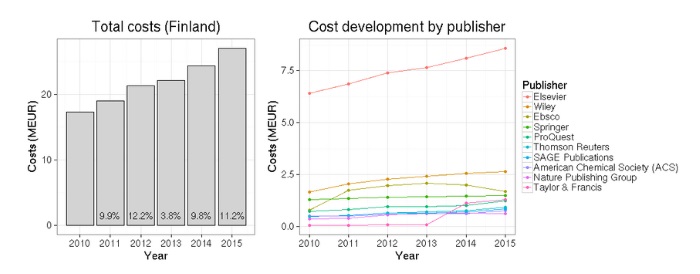 Une telle initiative s’inscrit dans le cadre de l’Open Science et de l’Open Data, comme préconisé dans le
Une telle initiative s’inscrit dans le cadre de l’Open Science et de l’Open Data, comme préconisé dans le  Ce document, annoncé en octobre 2015, est issu du travail du groupe d’experts de l’EUA sur l’Open Science.
Ce document, annoncé en octobre 2015, est issu du travail du groupe d’experts de l’EUA sur l’Open Science. Et «pour la première fois, un texte législatif gouvernemental est soumis à une discussion publique ouverte et interactive en ligne, avant son envoi au conseil d’État et son adoption en conseil des ministres.»
Et «pour la première fois, un texte législatif gouvernemental est soumis à une discussion publique ouverte et interactive en ligne, avant son envoi au conseil d’État et son adoption en conseil des ministres.» Dorénavant, les documents du domaine public des institutions citées peuvent être exploités gratuitement, y compris dans le cadre d’un usage commercial, sous la seule condition de mentionner leur provenance. Vous n’avez donc plus à nous demander de permission pour réutiliser les documents accompagnés de l’icône
Dorénavant, les documents du domaine public des institutions citées peuvent être exploités gratuitement, y compris dans le cadre d’un usage commercial, sous la seule condition de mentionner leur provenance. Vous n’avez donc plus à nous demander de permission pour réutiliser les documents accompagnés de l’icône 
